This project contains scripts to demonstrate basic PyTorch usage. The code requires python 3, numpy, and pytorch.
Manual vs. PyTorch Backprop Calculation
To compare a manual backprop calculation with the equivalent PyTorch version, run:
python backprop_manual_calculation.py
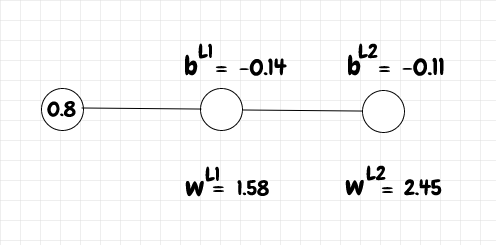
w_l1 = 1.58
b_l1 = -0.14
w_l2 = 2.45
b_l2 = -0.11
a_l2 = 0.8506
updated_w_l1 = 1.5814
updated_b_l1 = -0.1383
updated_w_l2 = 2.4529
updated_b_l2 = -0.1062
updated_a_l2 = 0.8515
and
python backprop_pytorch.py
network topology: Net(
(hidden_layer): Linear(in_features=1, out_features=1, bias=True)
(output_layer): Linear(in_features=1, out_features=1, bias=True)
)
w_l1 = 1.58
b_l1 = -0.14
w_l2 = 2.45
b_l2 = -0.11
a_l2 = 0.8506
updated_w_l1 = 1.5814
updated_b_l1 = -0.1383
updated_w_l2 = 2.4529
updated_b_l2 = -0.1062
updated_a_l2 = 0.8515
Blog post: PyTorch Hello World
MNIST Recognition
The next examples recognize MNIST digits using a dense network at first, and then several convolutional network designs (examples are adapted from Michael Nielsen's book, Neural Networks and Deep Learning).
I've added additional data normalization to the input since the original blog articles were published, using the code below (common.py):
normalization = transforms.Normalize((0.1305,), (0.3081,))
transformations = transforms.Compose([transforms.ToTensor(), normalization])0.1305 is the average value of the input data and 0.3081 is the standard deviation relative to the values generated just by applying transforms.ToTensor() to the raw data. The data_normalization_calculations.md file shows an easy way to obtain these values.
To train a fully connected network on the MNIST dataset (as described in chapter 1 of Neural Networks and Deep Learning, run:
python pytorch_mnist.py
Test data results: 0.9758
Blog post: PyTorch Image Recognition with Dense Network
To train convolutional networks (as described in chapter 6), run the following.
Simple network:
python pytorch_mnist_convnet.py
Test data results: 0.9891
Two convolutional layers:
python pytorch_mnist_convnet.py --net 2conv
Test data results: 0.9913
Two convolutional layers with ReLU:
python pytorch_mnist_convnet.py --net relu --lr 0.03 --wd 0.00005
Test data results: 0.993
Two convolutional layers and extended training data:
python pytorch_mnist_convnet.py --net relu --lr 0.03 --wd 0.00005 --extend_data
Test data results: 0.9943
Final network:
python pytorch_mnist_convnet.py --net final --epochs 40 --lr 0.005 --extend_data
Test data results: 0.9964
Blog post: PyTorch Image Recognition with Convolutional Networks.