Tic-Tac-Toe with the Minimax Algorithm
Tic-Tac-Toe (4 Part Series)
1. Tic-Tac-Toe with the Minimax Algorithm
In this article, I’d like to show an implementation of a tic-tac-toe solver using the minimax algorithm. Because it’s such a simple game with relatively few states, I thought that tic-tac-toe would be a convenient case study for machine learning and AI experimentation. Here I’ve implemented a simple algorithm called minimax.
The basic idea behind minimax is that we want to know how to play when we assume our opponent will play the best moves possible. For example, let’s say it’s X’s turn and X plays a particular move. What’s the value of this move? Suppose that O can respond in one of two ways: In the first case, O wins on the next move. The other move by O leads to a win by X on the following move. Since O can win, we consider the original move by X a bad one - it leads to a loss. We ignore the fact that X could win if O makes a mistake. We’ll define a value of 1 for a win by X, -1 for a win by O, and 0 for a draw. In the above scenario, since O can win on the next move, the original move by X is assigned a value of -1.
The minimax algorithm applies this strategy recursively from any given position - we explore the game from a given starting position until we reach all possible end-of-game states. We can represent this as a tree, with each level of the tree showing the possible board positions for a given player’s turn. When we reach an end-of-game state, there’s no choice to be made, so the value is the game result, that is 1 if X won, -1 if O won, and 0 if it was a draw. If it is X’s turn and it’s not a final board state, we choose the maximum of the values of the next possible moves from that position in the tree. This represents the best possible option for X. If it is O’s turn, then we choose the minimum of these values, which is the best option for O. We keep propagating the position values upward toward the root position, alternating between maximum and minimum values as we go - which is of course where the minimax algorithm gets its name.
The diagram below shows an example of minimax applied to a board position:
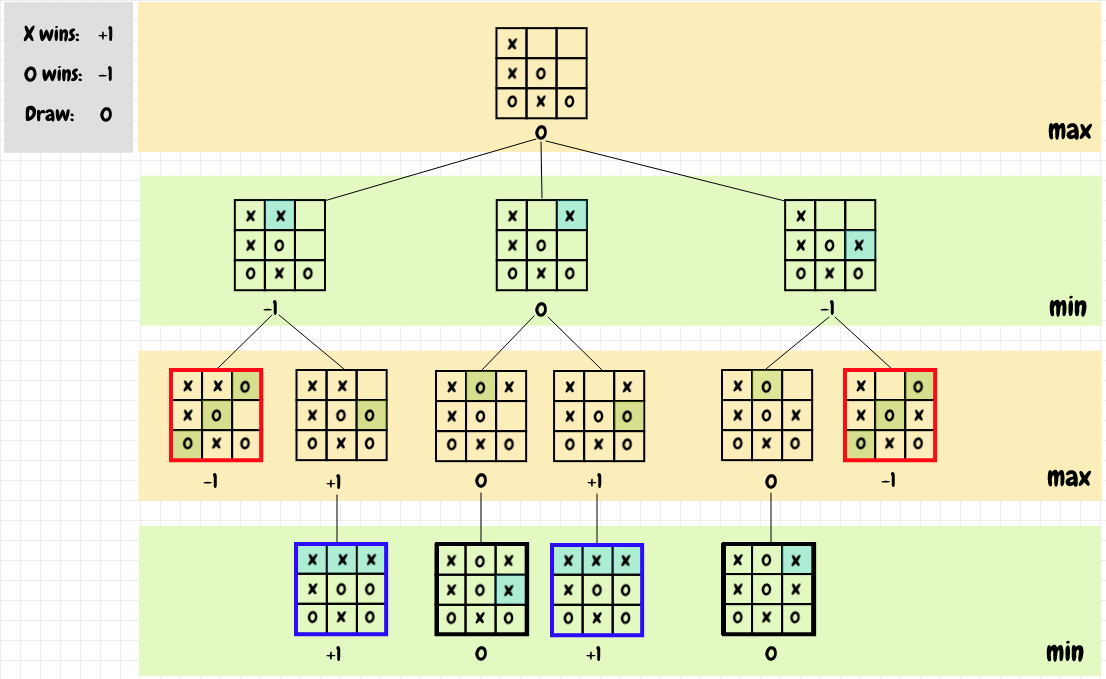
If the position is an end-of-game state, then the value of that position is the result of that game - that’s the terminating condition for the recursive calls. Once we’ve reached the end-of-game positions, we can work our way back up toward the root position. For positions in the max levels of the tree - where it is X’s turn - we choose the move with the maximum value from the possible continuations. For the positions in the min levels of the tree - where it is O’s turn - we take the minimim value. In each case, we are looking for the best possible result for the current player’s next move. As we can see, the best X can do in the diagram (as long as O doesn’t make a mistake) is to get a draw by playing in the top right-hand corner of the board.
It’s worth emphasizing that minimax works fine for a toy scenario like tic-tac-toe: There are few distinct game positions - 765 if we take rotation and reflection symmetry into account. For more complex scenarios, including games like chess and go, minimax would, at the very least, have to be combined with other techniques. I haven’t implemented it here, but alpha-beta pruning can be used to reduce the number of positions that need to be visited. The overall idea is that if we know that exploring a subtree won’t produce a better result than what we’ve already got, then we don’t need to bother with it. There are additional heuristics as well. We can limit the depth of search, and once we hit that limit, we can use a heuristic to estimate the likely value of the position. This idea has been used extensively in chess engines like Stockfish. MCTS is another technique that can be applied to simplify scenarios where minimax would result in too many combinations to keep track of. These days, for games like chess and go, deep learning has proven remarkably effective. In fact, it’s far more effective than any other known technique.
Let’s briefly look at the code needed to implement minimax. Note that this code is not written for maximum efficiency, just to illustrate the basic concepts. The project is available on github. This code is from the minimax.py file:
def play_minimax_move(board):
move_value_pairs = get_move_value_pairs(board)
move = filter_best_move(board, move_value_pairs)
return play_move(board, move)
play_minimax_move determines which move to play for a given board position. First it gets the values corresponding to each possible move, then plays the move with the maximum value if it’s X’s turn, or the move with the minimum value if it’s O’s turn.
get_move_value_pairs gets the value for each of the next moves from the current board position:
def get_move_value_pairs(board):
valid_move_indexes = get_valid_move_indexes(board)
assert not_empty(valid_move_indexes), "never call with an end-position"
move_value_pairs = [(m, get_position_value(play_move(board, m)))
for m in valid_move_indexes]
return move_value_pairs
get_position_value, below, either obtains the value of the current position from a cache, or calculates it directly by exploring the game tree. Without caching, playing a single game takes about 1.5 minutes on my computer. Caching takes that down to about 0.3 seconds! A full search will encounter the same position over again many times. Caching allows us to speed this process up considerably: If we’ve seen a position before, we don’t need to re-explore that part of the game tree.
def get_position_value(board):
cached_position_value, found = get_position_value_from_cache(board)
if found:
return cached_position_value
position_value = calculate_position_value(board)
put_position_value_in_cache(board, position_value)
return position_value
calculate_position_value finds the value for a given board when it is not already in the cache. If we’re at the end of a game, we return the game result as the value for the position. Otherwise, we recursively call back into get_position_value with each of the valid possible moves. Then we either get the minimum or the maximum of all of those values, depending on who’s turn it is:
def calculate_position_value(board):
if is_gameover(board):
return get_game_result(board)
valid_move_indexes = get_valid_move_indexes(board)
values = [get_position_value(play_move(board, m))
for m in valid_move_indexes]
min_or_max = choose_min_or_max_for_comparison(board)
position_value = min_or_max(values)
return position_value
We can see below that choose_min_or_max_for_comparison returns the min function if it is O’s turn and max if it is X’s turn:
def choose_min_or_max_for_comparison(board):
turn = get_turn(board)
return min if turn == CELL_O else max
Going back to caching for a moment, the caching code also takes into account positions that are equivalent. That includes rotations as well as horizontal and vertical reflections. There are 4 equivalent positions under rotation: 0°, 90°, 180°, and 270°. There are also 4 reflections: Flipping the original position horizontally and vertically, and also rotating by 90° first, then flipping horizontally and vertically. Flipping the remaining rotations is redundant: Flipping the 180° rotation will produce the same positions as flipping the original position; flipping the 270° rotation will produce the same positions as flipping the 90° rotation. Without taking into account rotation and reflection, a single game takes approximately 0.8 seconds on my computer, compared to the 0.3 seconds when caching is also enabled for rotations and reflections. get_symmetrical_board_orientations obtains all of the equivalent board positions so they can be looked up in the cache:
def get_symmetrical_board_orientations(board_2d):
orientations = [board_2d]
current_board_2d = board_2d
for i in range(3):
current_board_2d = np.rot90(current_board_2d)
orientations.append(current_board_2d)
orientations.append(np.flipud(board_2d))
orientations.append(np.fliplr(board_2d))
orientations.append(np.flipud(np.rot90(board_2d)))
orientations.append(np.fliplr(np.rot90(board_2d)))
return orientations
If you’re interested in having a closer look, the github repo with all of the code for this project is available at:
Experimenting with different techniques for playing tic-tac-toe
Demo project for different approaches for playing tic-tac-toe.
Code requires python 3, numpy, and pytest. For the neural network/dqn implementation (qneural.py), pytorch is required.
Create virtual environment using pipenv:
Install using pipenv:
pipenv shellpipenv install --dev
Set PYTHONPATH to main project directory:
- In windows, run
path.bat
- In bash run
source path.sh
Run tests and demo:
- Run tests:
pytest
- Run demo:
python -m tictac.main
- Run neural net demo:
python -m tictac.main_qneural
Latest results:
C:\Dev\python\tictac>python -m tictac.main
Playing random vs random:
-------------------------
x wins: 60.10%
o wins: 28.90%
draw : 11.00%
Playing minimax not random vs minimax random:
---------------------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax random vs minimax not random:
---------------------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax not random vs minimax not random:
-------------------------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax random vs minimax random:
-----------------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax random vs random:
---------------------------------
x wins: 96.80%
o wins: 0.00%
draw : 3.20%
Playing random vs minimax random:
---------------------------------
x wins: 0.00%
o wins: 78.10%
draw : 21.90%
Training qtable X vs. random...
700/7000 games, using epsilon=0.6...
1400/7000 games, using epsilon=0.5...
2100/7000 games, using epsilon=0.4...
2800/7000 games, using epsilon=0.30000000000000004...
3500/7000 games, using epsilon=0.20000000000000004...
4200/7000 games, using epsilon=0.10000000000000003...
4900/7000 games, using epsilon=2.7755575615628914e-17...
5600/7000 games, using epsilon=0...
6300/7000 games, using epsilon=0...
7000/7000 games, using epsilon=0...
Training qtable O vs. random...
700/7000 games, using epsilon=0.6...
1400/7000 games, using epsilon=0.5...
2100/7000 games, using epsilon=0.4...
2800/7000 games, using epsilon=0.30000000000000004...
3500/7000 games, using epsilon=0.20000000000000004...
4200/7000 games, using epsilon=0.10000000000000003...
4900/7000 games, using epsilon=2.7755575615628914e-17...
5600/7000 games, using epsilon=0...
6300/7000 games, using epsilon=0...
7000/7000 games, using epsilon=0...
Playing qtable vs random:
-------------------------
x wins: 93.10%
o wins: 0.00%
draw : 6.90%
Playing qtable vs minimax random:
---------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing qtable vs minimax:
--------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing random vs qtable:
-------------------------
x wins: 0.00%
o wins: 61.00%
draw : 39.00%
Playing minimax random vs qtable:
---------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax vs qtable:
--------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing qtable vs qtable:
-------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
number of items in qtable = 747
Training MCTS...
400/4000 playouts...
800/4000 playouts...
1200/4000 playouts...
1600/4000 playouts...
2000/4000 playouts...
2400/4000 playouts...
2800/4000 playouts...
3200/4000 playouts...
3600/4000 playouts...
4000/4000 playouts...
Playing random vs MCTS:
-----------------------
x wins: 0.00%
o wins: 63.50%
draw : 36.50%
Playing minimax vs MCTS:
------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax random vs MCTS:
-------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing MCTS vs random:
-----------------------
x wins: 81.80%
o wins: 0.00%
draw : 18.20%
Playing MCTS vs minimax:
------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing MCTS vs minimax random:
-------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing MCTS vs MCTS:
---------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
C:\Dev\python\tictac>python -m tictac.main_qneural
Training qlearning X vs. random...
200000/2000000 games, using epsilon=0.6...
400000/2000000 games, using epsilon=0.5...
600000/2000000 games, using epsilon=0.4...
800000/2000000 games, using epsilon=0.30000000000000004...
1000000/2000000 games, using epsilon=0.20000000000000004...
1200000/2000000 games, using epsilon=0.10000000000000003...
1400000/2000000 games, using epsilon=2.7755575615628914e-17...
1600000/2000000 games, using epsilon=0...
1800000/2000000 games, using epsilon=0...
2000000/2000000 games, using epsilon=0...
Training qlearning O vs. random...
200000/2000000 games, using epsilon=0.6...
400000/2000000 games, using epsilon=0.5...
600000/2000000 games, using epsilon=0.4...
800000/2000000 games, using epsilon=0.30000000000000004...
1000000/2000000 games, using epsilon=0.20000000000000004...
1200000/2000000 games, using epsilon=0.10000000000000003...
1400000/2000000 games, using epsilon=2.7755575615628914e-17...
1600000/2000000 games, using epsilon=0...
1800000/2000000 games, using epsilon=0...
2000000/2000000 games, using epsilon=0...
Playing qneural vs random:
--------------------------
x wins: 98.40%
o wins: 0.00%
draw : 1.60%
Playing qneural vs minimax random:
----------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing qneural vs minimax:
---------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing random vs qneural:
--------------------------
x wins: 0.00%
o wins: 75.40%
draw : 24.60%
Playing minimax random vs qneural:
----------------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing minimax vs qneural:
---------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Playing qneural vs qneural:
---------------------------
x wins: 0.00%
o wins: 0.00%
draw : 100.00%
Below are the winning percentages for the different combinations of minimax and random players, with 1000 games played for each combination:
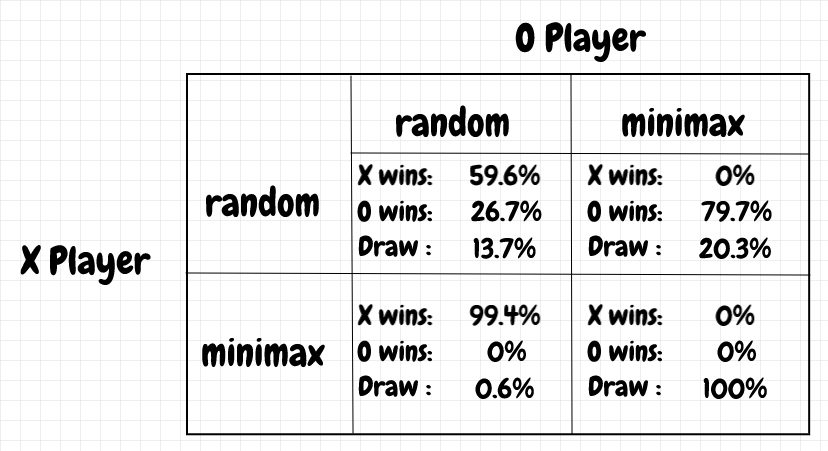
We can see that if both players play perfectly, only a draw is possible, but X is more likely to win if both players play at random.